AI Server Types
AI Infrastructure - Just a bunch of GPUs?
AI optimized infrastructure is oten thought to simply be “a bunch of GPUs”. And while GPUs are often involved, thinking it as such is a surface level thinking.
To understand why that statement gets thrown around you need to understand what an AI model is, how it gets built and how it gets used.
An AI model is simply a binary. There are different types of formats (ex. Checkpoint’s), but for the purpose of this article, think of them as a binary. They are produced by a training cluster, which is a difficult and intensive process. Once training is completed, the binary is sent to a distributor (ex. HuggingFace). It is then available to be used.
When a model is used, that’s called inferencing. The user can send tokens into
a model to ask it a series of questions. Usually inference is a multi step
process to produce better, finer grained results.
The act of inferencing is generally fairly light weight compared to training. It is also something that can be widely distributed.
I like to use the following to better visualize:
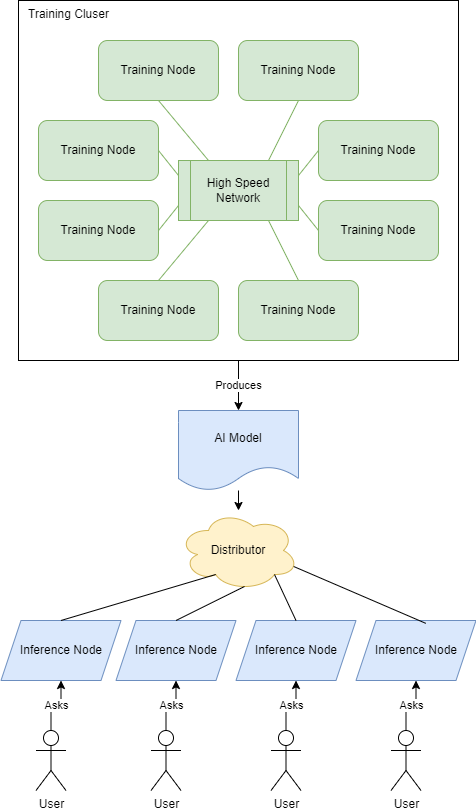
Training produces a model. The model is distributed. From there, inference is run against it.
Building Effecient Training Infrastructure
I don’t think people understand the amount of infrastructure required to train brand new, multi billion parameter models.
The analogy I use is that we are trying to build a lifetime of knowledge into a model in as short a period of time as possible. That lifetime of knowledge usually takes, well, a lifetime. But we are impatient beings by nature and want the result in days or weeks - not years or decades.
Fortunately for us, training is highly scalable and is sensitive to a few key elements within your infrastructure. It requires:
- High speed memory (think multiple hundred GB/s of memory bandwidth - or even TB/s)
- High FP/INT speeds
- Low latency / High Bandwidth communication for multi node training
The first thing we need are accelerators.
Picking the Accelerator
Let’s start by looking at previous/current generation accelerators:
| Card | Memory Size | Memory Speed | FP16 Perf | INT8 Perf | Reference |
|---|---|---|---|---|---|
| NVIDIA V100 | 32 GB | 900 GB/s | 31.4 TFlops | 62.8 TOPs | Link |
| AMD MI250 | 128 GB | 3.2 TB/s | 362 TFlops | 362 TOPs | Link |
| NVIDIA A100 | 80 GB | 2 TB/s | 624 TFlops | 1248 TOPs | Link |
Picking the right accelerator has orders of magnitudes impact on your workload training. The A100 runs circles around the V100 in it’s performance.
But I hate to break it to you, it’s not enough. Training large multi billion parameter models is not a single accelerator exercise.
Picking the Server
The next component that needs to be considered is the server. Typical designs have 8+ accelerators connected on a high speed in-system fabric. An example here is the NVIDIA DGX node. This server has 8 GPUs connected together on a high speed “NVLink” fabric. All of the GPUs can directly talk to each other at 600 GB/s.
Additionally, in this specific system there are 4 PLX switches to hang NICs and NVMe disks off of. These allow for the NVIDIA CUDA stack to utilize their “GPUDirect” technology. This lets the GPUs on the same PCIe switches talk directly to the NICs/NVMe disks without proxying the communication through the host CPU. This allows for a significant speed up in cross accelerator communication.
Other vendors have similar technologies - such as AMD’s Infinity Fabric where they have multiple Instinct accelerators communicating with each other on PCIe switches.
Using one of these servers allows you to increase the training speed by 8x - since training itself is highly parallel. However, that’s not enough generally.
Choosing the right fabric
The worlds largest models need thousands of state of the art accelerators. To meet the needs of those models, an ultra fast network needs to be developed.
Remember in the previous system that there were multiple PCIe switches connected directly to the GPUs? Well each of those switches also typically gets a NIC. Some training nodes have as many NICs as they have GPUs. That allos for every GPU to communicate with the network without performing a PCIe switch hop (lower latency, possibly higher bandwidth).
A proper training network should have the following capabilities:
- Tight cohesion between the accelerators and the NICs within the training node
- Remote Direct Memory Access (RDMA)
- A GPUDirect like technology
- Low latency (couple micro seconds ideally)
- Ultra high bandwidth (400 Gbps+ can’t come fast enough)
Frankly, a lot of training is done on Infiniband networks. Over time though RoCE is starting to be used in cloud environments. When deployed correctly, RoCE can provide many of the Infiniband benefits, but also additionally the cloud scale capabilities.
Put it altogether and you get a Training Cluster
Training models is done generally on clusters. These provide excellent environments to build a model reasonably quickly. The faster the cluster, the shorter we need to wait to train the model.
Using the Model
The model produced by the training cluster is used to perform inference against. Put simply, inference is the act of asking the model a question and getting a result. It’s generally a relatively light weight exercise on a complicatd baselien set of data.
It’s like asking what you want for dinner. You can probably answer that immediately, but you have a life time of growth influencing the response to that question. What you want to eat is probably really easy to answer, but it took you a life time to figure out what answer you were going to give in that moment, in that circumstance.
Not all models require GPUs or accelerators. In fact, there are many emerging models (ex. many conversational AI bots) can increasingly run on CPUs. With AVX-512 acceleration, and even new technologies like Intel Advanced Math Extensions (AMX) - there is a path for many models to run on CPUs. But there are some models that will only thrive on GPUs.
For those you want to make sure that you have enough memory to fit the entire model in the GPU, that you have the memory bandwidth, and the performance on the card to support getting results quickly.
As an anecdote, you may find that for certain very large models you would still use an NVIDIA A100 GPU. For the highest end models, it is a fantastic inference card. However it’s probably overkill for most AI models. Your CPU, a 24 or 48 GB GPU, etc… will likely handle 99.9% inference needs (for now).
What you do want to make sure is that you deploy your inference hardware where you need it. The model is a reasonably portable asset. Move it to a private network, to a network of edge nodes, etc… Wherever you need it.
My common phrase is to train at the core, inference at the edge. Use your training cluster to develop rapidly. But deploy it across a wide ranging network that meets your user where they need to be.
I’m excited to see what the next few years bring in terms of pushing the envelope. AI has certainly changed the way we are building infrastructure, and it will benefit traditional computing as well.